ディープラーニングができる環境を構築してみましょう!


![]()
近年膨大なデータを基に,いろいろなアルゴリズムを見直す流れができています。この時に用いられる機械学習の手法が,俗に言う「ディープラーニング」です。
膨大なデータの因果を基に,正しい数式を類推する作業を指し,実際に使われているデータや要素はとても多く,大規模なサーバー群によって運用されています。こう言うとなんだか遠い世界のような感じがしますが,実は一般的なパソコンでも同じような環境を構築して動かすことができます。
そこで今回は,弊社でもディープラーニングを勉強するための環境づくりを行ってみました。これからPythonを使ってデータ分析をしたい方のお役に立てば嬉しいです。
用意する環境
ディープラーニングでよく話題に上がるフレームワークは「TensorFlow」,「Chainer」の二つだと言われています。TensorFlowはいくつかのプログラミング言語をサポートしていますが,ChainerはPython専用のフレームワークです。
そのため、TensorFlowを特定の言語で実行するのでなければ、Pythonで両方のフレームワークを使用できるようにする方が,開発環境としては編集がしやすい,結果も保存しておけるなどの利点があります。以上の理由から,今回はプログラム言語としてPythonを、プログラムの検証ツールとしてJupyter Notebookを使用します。
用意するもの
Ubuntu(バージョンは16.04以降がおすすめです,もうすぐ18.04 LTSが出る予定です。)
※RedHat系のCentOS 7でも可能ですが,yumのデフォルトではパッケージがインストールできないため,今回はより簡便なUbuntuをメインに用います。
インストール手順
Ubuntu系
ubuntuのパッケージ管理ソフトウェア『apt』を使って主なパッケージはインストールします。
ubuntuでは、pythonがver2関連とver3関連が両立できるため、両方とも使用できるようにインストールします。
# apt install python-pip python-pandas python-sklearn
# apt install python3-pip python3-pandas python3-sklearn
# apt install jupyter-notebook
→依存関係で必要なパッケージもまとめてインストールできます。aptでインストールできないchainerとTendsorFlowをpipを使用してインストールします。
# pip install chainer tensorflow pandas-ml
# pip3 install chainer tensorflow pandas-ml
これで、chainerなどを動かすのに必要であろうパッケージがインストールされます。
CentOS系
epelのウェブサイトからリポジトリ登録用rpmをダウンロードし、実行します。
その後ターミナルを開いて,
# yum install python-pip
pipはPythonのパッケージ管理ソフトウェアで、ここからライブラリを追加します。
pip install pip –upgrade
pip install jupyter matplotlib sklearn chainer scipy pandas-ml
使用方法
基本的には,ターミナルを起動して以下のコマンドを実行することでサービスが起動します。同時に初期ページが開いた状態のブラウザが表示されます。
jupyter-notebook
デフォルトフォルダを変更します。
jupyter-notebook –notebook-dir=”フォルダへのパス”
起動時からデーモンとして起動する場合は以下のコマンドを使います。
jupyter-notebook –no-browser &
内容のテストは,ブラウザに以下のアドレスを入力してアクセスできます。
http://localhost:8888
制限がなければ同じネットワークからIPアドレスを直接指定して他の端末からもアクセスできます。トップページではデフォルトフォルダのファイル一覧が表示されます。
ダッシュボード
ここではフォルダに存在するファイルの一覧が表示されます。

ノートブックファイルである場合,それが実行中であるかも表示してくれます。
右上のNewボタンをクリックするとファイルやフォルダの作成が行えます。
作成できるファイルは,使用できるプログラム言語のノートブックとテキストファイルです。
また,terminalを選択することでブラウザ上でターミナルを使用することができます。
ノートブックUI(ユーザーインターフェース)

一つのノートブックにプログラムなどを記述していきます。プログラムを分割して,特定のソースだけを実行することができます。
この一つの記述単位をセルといいます。起動中のノートブックは,今まで実行された全てのセルの結果を保持しています。
保持している内容はセルの実行ごとに上書きされます。
例えば,同じ変数名で違う値を入力し直した場合,値は上書きされます。
セルはあくまで独立したプログラム文であり,セルの並び=実行順番である必要はありません。ただし,一括実行などの場合は上のセルから順に処理が行われます。
実行したセルに出力を行うプログラムがあった場合,その出力がセルの下部に表示されます。
ノートブック編集画面には,テキストメニューとアイコンメニューが存在します。テキストメニューはカテゴリごとに分割されており,カテゴリをクリックすることで実行できる指示の一覧
が表示されます。
アイコンメニューはテキストメニューの中で特に使用されるであろう機能が表示されています。
基本的な流れ
- セルにプログラムを記述する
- 実行する、あるいは新たなセルに追記する
の繰り返しになります。
実験の過程をすべて追う場合には同じ内容のセルをコピーして編集することになるでしょう。
最終的な一本のプログラムを目指す場合は,同じセル上で編集を行うことで見やすくすることもできます。
実行
セルにプログラムを書いたら,それを実行します。テキストメニューではCellを選択し以下の実行方法のうちどれかを選択して実行します。
Run Cells – セルを実行します
Run Cells and Select Below – セルを実行し、次のセルへ移動します
Run Cells and Insert Below – セルを実行し、からのセルを現在のセルの直下に作成し移動します
アイコンメニューでは左から8番目が『Run Cells and Select Below 』になります。
処理中、中断
処理途中のセルにはinの表示が,in[] から in[*] に変わります。
無限ループに陥っているなどで,処理を中断させたい場合は,kernel.interruptをメニューから実行することで中断できます。
中断された段階でセルに入力番号が振られ,出力に KeyboardInterrupt: のエラー出力がされます。
セルの編集
セルはコピー,切り取り,貼り付け,上下の移動がアイコンメニューから可能です。プログラムとして並び替える時や試行錯誤中にセルを複製する時などに使用します。
セルを対象に取る時はセルを左クリックします。テキストボックスをクリックし編集中の場合は左が緑に,選択状態の場合は青になります。
実行例
テストとして簡単に動かした場合のスクリーンショットが以下になります。
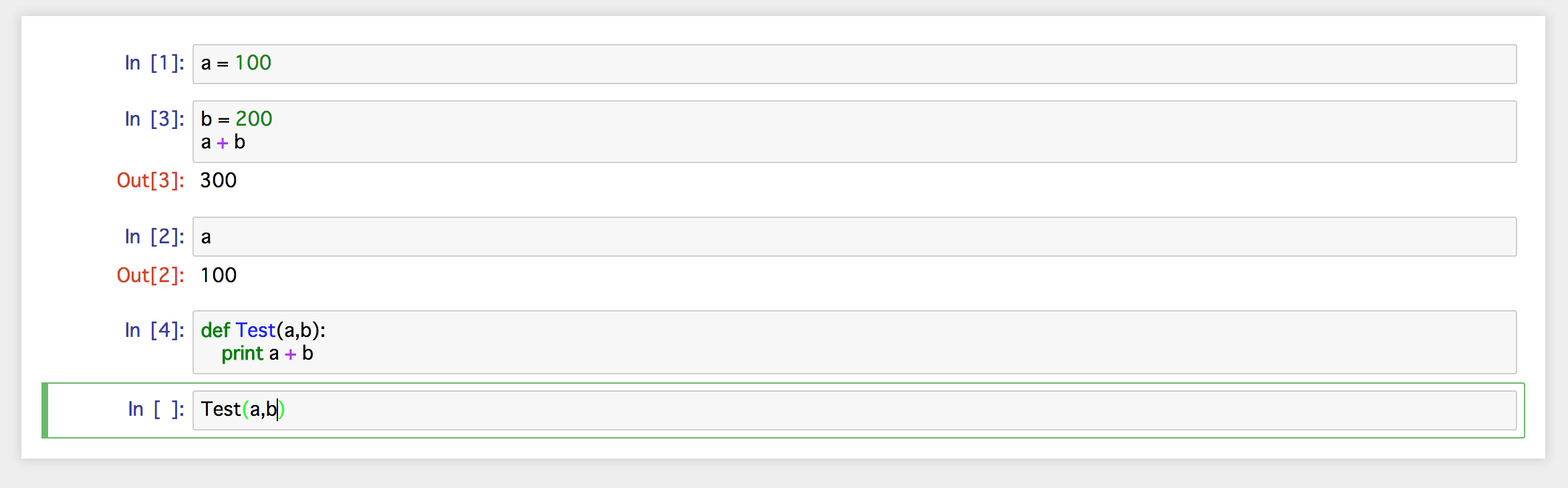
まず一つ目のセルで「変数a」に「100」という値を代入し,実行します。
次のセルで変数の身を記述していますが,最後の一行が数字,計算,変数,英数字で始まらない文字列であった場合は echo() と同じように出力に表示されます。

次の画像では,一行目を選択し直した後で『insert cell below』でセルを追加しています。
 追加したセルに「変数b」を定義し,「変数a」と「変数b」を加算を実行して表示します。
追加したセルに「変数b」を定義し,「変数a」と「変数b」を加算を実行して表示します。
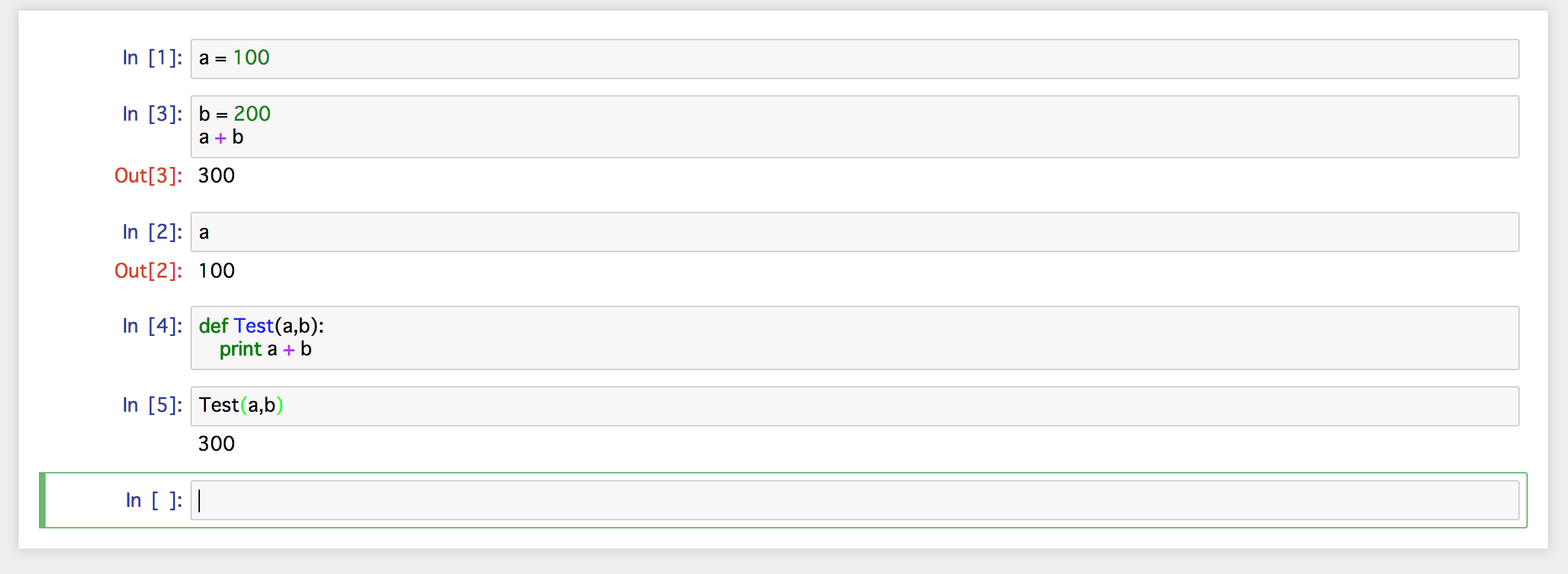
既に「変数a」は定義されているため,実行結果は次の画像の通り,正常に計算できます。
 その次の画像は関数を定義したセルと,その関数を実行するセルの順で実行し,こちらも問題なく動作しています。
その次の画像は関数を定義したセルと,その関数を実行するセルの順で実行し,こちらも問題なく動作しています。
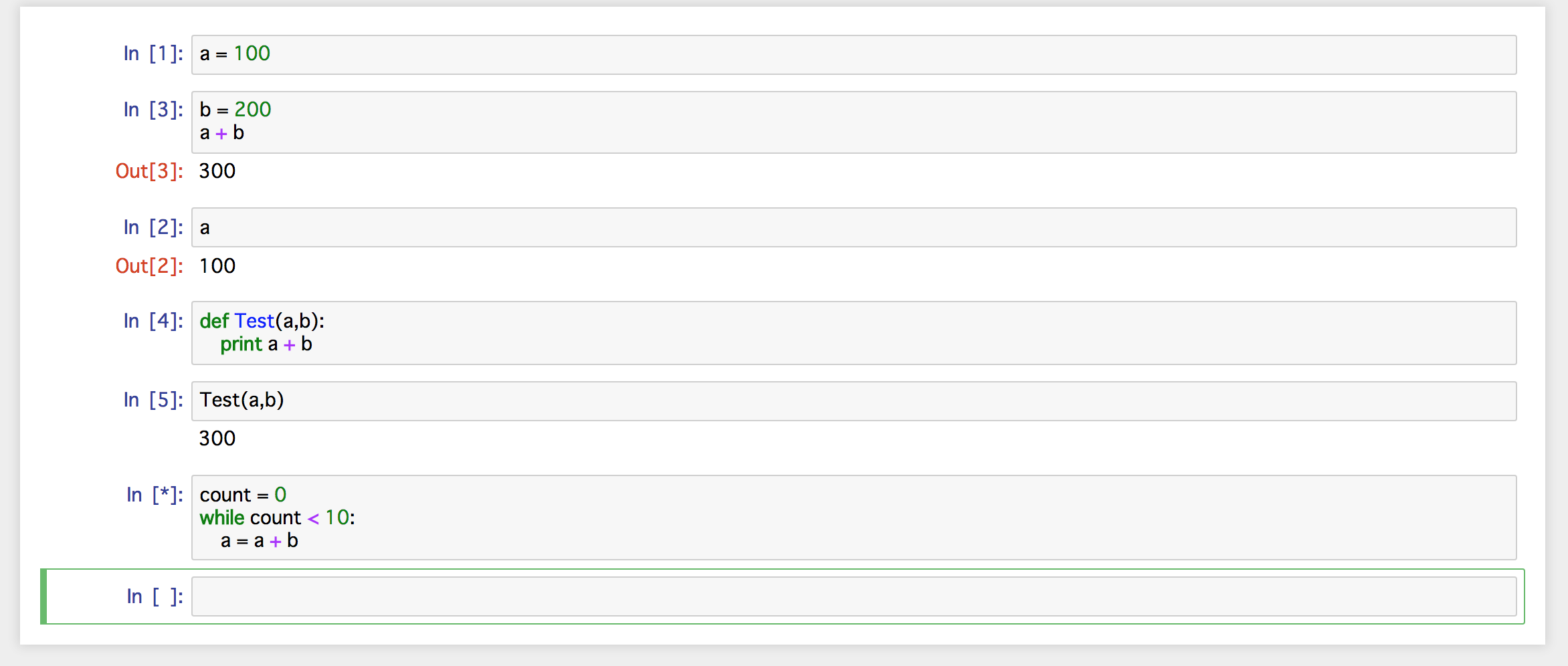
 次の画像では終わらない while文 を実行し続け,セルの in[] が in[*] になっています。
次の画像では終わらない while文 を実行し続け,セルの in[] が in[*] になっています。
 最後の画像では、『kernel interrupt』を行い終了しています。
最後の画像では、『kernel interrupt』を行い終了しています。

おわりに
いかがでしたでしょうか。
Jupyter Notebookは,プログラムの実行環境としてはとても使い勝手がいいものだと思います。ディープラーニングはデータが大きいと処理時間も必要な処理能力も増大していきます。
今回店頭にて実験できる環境を弊社のカスタマイズPCであるPOWERSTEP Towerにて構築しました。処理用にGPUは積んでいないものの、そこそこの処理はできるはずです。
このブログでご紹介したデモ環境を,来週2/26(月)〜来月3/9まで弊社店頭で公開します。
実験はご自由に行っていただいて構いませんが、作成したノートブックファイルの保存、受け渡しなどは申し訳ありませんがご遠慮いただく形になります。何卒ご了承いただきますようお願いいたします。
この機会に是非店頭までお越しください,お待ちしております!
2020/9/23 追記
弊社では、上記製品をアップデートした新しい Towerををご用意しています。